app下载
app下载


11.5典型实例20:fpga片上硬件乘法器的使用
11.5.1实例的内容及目标
1.实例的主要内容
在fpga dsp系统设计系统中,fpga经常作为dsp的协处理器来辅助完成一些计算任务。而这些计算工作中最消耗时间的就是乘法运算,因此本实例的主要内容就是帮助读者学会调用硬件乘法ip核。
2.实例目标
通过本实例,读者应达到以下目标。
·了解硬件乘法器对算法的加速作用。
·掌握fpga片上硬件乘法器ip的调用方法。
11.5.2硬件乘法ip的使用方法
1.生成硬件乘法器
如图11.12所示,在“newsource”里面选择“ip(coregenarchitecturewizard)”,在右边的文件名里面输入“multiply”,单击“next”按钮,打开如图11.13所示的ip核类型选择对话框。
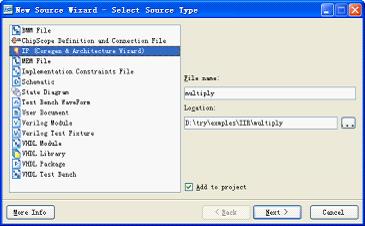
图11.12新建ip核文件
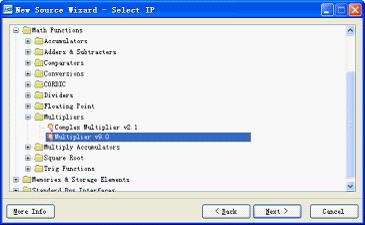
图11.13新建乘法器ip核
在ip核类型选择界面里面选择mathfunctions→multipliers→multiplierv7.0,单击“next”按钮,打开乘法器ip核生成向导,如图11.14所示。
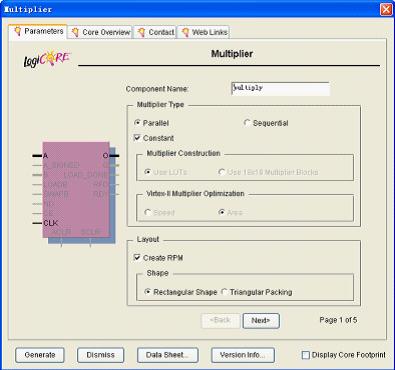
图11.14乘法器生成向导
在上面对话框里,“componentname”是要生成的模块的名称。“parallel”和“sequential”两个选项是用来选择乘法器模式的,选择并行结构可以加快乘法器的速度,但是同时要多占用一些资源。选择“constant”选项我们会发现乘法器的b输入端口被屏蔽掉了,这时b将作为一个固定输入。
如果不选择“constant”选项,可以在下面的乘法器结构框里面选择乘法器使用的资源种类,选择“useluts”将使用片上存储器资源,选择“use18*18multiplierblocks”将使用fpga自带的dsp模块。“virtex-iimultiplieroptimization”框里面的选项只有在使用virtex-ii族器件的时候才能使用。
前面选择了constant选项,在这个对话框里面就要对乘法器的b输入进行设置,在constantvalue后面输入b端口输入的数值(十进制),如图11.15所示。
在如图11.16所示的对话框里面设置输入口a的位宽和形式。
在如图11.17所示的对话框里面设置输出口的位宽和是否使用寄存器(使用输出寄存器的时候由q口输出,不使用输出寄存器的时候由o口输出)。
在如图11.18所示的对话框里面选择“minimumpipelining”可以看见在最下面的“information”框里面的输出延迟达到最小为1。在“registeroption”栏里面可以设置同步复位,异步复位和时钟使能。
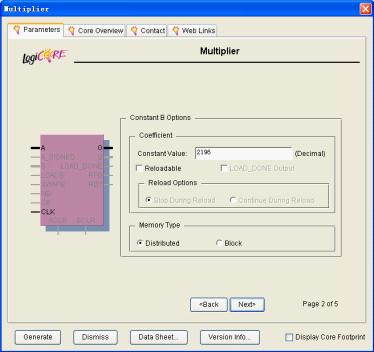
图11.15设置端口b参数
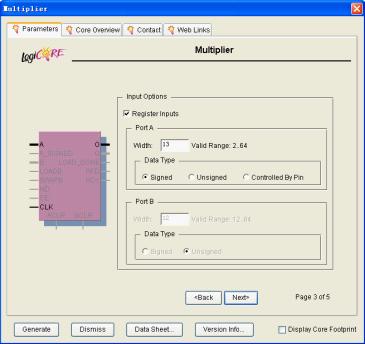
图11.16设置端口a参数
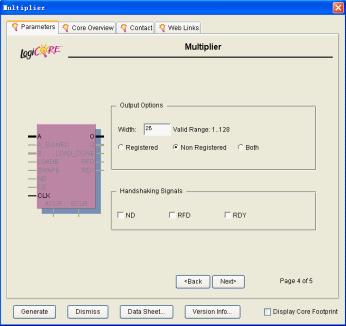
图11.17设置输出端口
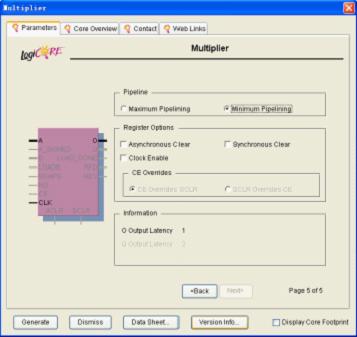
图11.18其他参数设置
配置完成以后单击“generate”按钮就可以生成乘法器了。
2.使用硬件乘法器
本实例以一个iir数字滤波的设计为例来演示硬件乘法器的使用方法。直接打开实例的工程文件,如图11.19所示。其中iir.v是iir滤波器的设计文件,test.tbw为测试文件。
图11.19iir数字滤波器工程目录
在iir.v的文件中,可以看到硬件乘法器的调用方法。
reg[12:0]x1,x2,x3;//定义乘数a
reg[12:0]y1,y2,y3;
reg[12:0]q1,q2,q3;
wire[25:0]mul[10:1];//定义乘法的输出结果
multiplym0(.clk(clk),.a(x1),.o(mul[1]));//乘法器的调用,输入为a,输出为o
multiplym1(.clk(clk),.a(x2),.o(mul[2]));
multiplym2(.clk(clk),.a(x3),.o(mul[3]));
multiplym3(.clk(clk),.a(y1),.o(mul[4]));
multiplym4(.clk(clk),.a(y2),.o(mul[5]));
multiplym5(.clk(clk),.a(y1),.o(mul[6]));
multiplym6(.clk(clk),.a(y2),.o(mul[7]));
multiplym7(.clk(clk),.a(y3),.o(mul[8]));
multiplym8(.clk(clk),.a(q1),.o(mul[9]));
multiplym9(.clk(clk),.a(q2),.o(mul[10]));
运行仿真后,可以得到输出结果如图11.20所示。

图11.20iir数字滤波器仿真结果
11.5.3小结
本节对生成和使用fpga的片上硬件乘法器ip核的方法做了介绍,并通过编译下载在红色飓风的开发板上实现了预定功能。








 热门文章
热门文章